LoG-VMamba —— 兼顾局部与全局依赖的医学图像分割新范式
0. 前言
在医学图像分割(MIS)领域,基于状态空间模型(SSM)的 Mamba 架构因其线性计算复杂度和全局建模能力备受关注 。然而,由于 Mamba 的顺序扫描本质,空间上相邻的像素在序列中可能相距甚远,导致局部依赖(Local Dependencies)难以保持 。
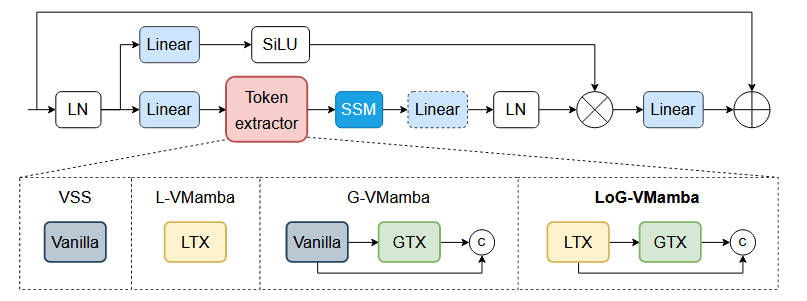
来自芬兰奥卢大学的研究团队提出了 LoG-VMamba,通过引入 LTX (局部令牌提取器) 和 GTX (全局令牌提取器),在不增加扫描策略复杂度的前提下,显著提升了分割性能 。
1. 核心架构逻辑实现
LoG-VMamba 的核心在于对 VSSBlock(Visual State Space Block)输入端的改造 。它摒弃了多向扫描,仅使用简单的单向水平扫描,通过 token 的预处理来增强特征 。、
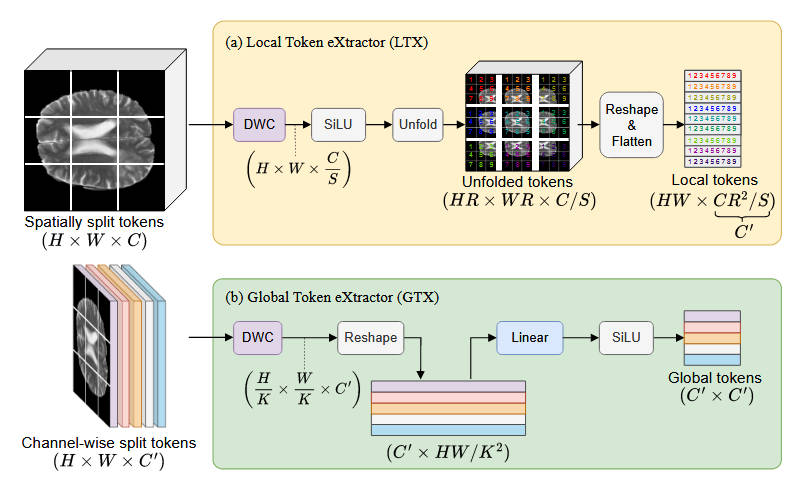
1.1 LTX (局部令牌提取器)
- 实现原理:利用深度卷积(DWC)压缩通道,随后使用 Unfold 操作(固定大小的R✖R卷积核)来复制和保留邻域 token 的空间关系 。
- 作用:显式地将空间相邻的 token 聚合在通道轴上,确保 Mamba 在线性扫描时能同时处理局部窗口内的信息 。
1.2 GTX (全局令牌提取器)
- 实现原理:通过带扩张率(Dilated)的深度卷积(DWC)进行空间压缩(步幅为 k✖k),随后通过线性层投影至特征空间 。
- 作用:生成代表全图上下文的“压缩全局令牌”,让 SSM 模块在到达序列末尾前就能提前访问全局感受野(GRF) 。
2. 核心代码实现 (基于原论文逻辑)
以下代码展示了 LoG-VMamba 中最关键的 LTX、GTX 模块以及如何将它们集成到 Mamba 块中的实现。
核心模块:LTX 与 GTX 的 PyTorch 实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class LTX(nn.Module):
"""局部令牌提取器 (Local Token eXtractor)"""
def __init__(self, in_channels, r=3, s=8):
super().__init__()
self.r = r # 窗口大小
self.s = s # 通道压缩因子
self.mid_channels = max(1, (in_channels * r * r) // s)
# 深度卷积压缩通道
self.dwc = nn.Conv2d(in_channels, in_channels // s, kernel_size=1)
self.silu = nn.SiLU()
# Unfold 操作保留空间近邻
self.unfold = nn.Unfold(kernel_size=r, padding=r // 2)
def forward(self, x):
# x shape: [B, C, H, W]
x = self.dwc(x)
x = self.silu(x)
# unfold 后 shape: [B, (C/S)*R*R, H*W]
x = self.unfold(x)
# 转置为 [B, L, C'] 格式供 Mamba 使用
return x.transpose(1, 2)
class GTX(nn.Module):
"""全局令牌提取器 (Global Token eXtractor)"""
def __init__(self, in_channels, k=5):
super().__init__()
# 使用带扩张率的卷积进行空间压缩
self.dwc = nn.Conv2d(in_channels, in_channels, kernel_size=k, stride=k)
self.linear = nn.Linear(in_channels, in_channels)
self.silu = nn.SiLU()
def forward(self, x):
# x 是来自 LTX 的 1D 序列 [B, L, C], 需要还原回 2D 进行处理
# 实际代码中 GTX 通常接收 LTX 处理后的特征图
x = self.dwc(x)
# 展平空间维度作为全局 Token
x = x.flatten(2).transpose(1, 2)
x = self.linear(x)
return self.silu(x)
class LoG_Module(nn.Module):
"""整合 LTX 和 GTX 的 Token 提取模块"""
def __init__(self, channels, r=3, s=8, k=5):
super().__init__()
self.ltx = LTX(channels, r, s)
# C' = C * R^2 / S
c_prime = (channels * r * r) // s
self.gtx = GTX(c_prime, k)
def forward(self, x):
# 提取局部令牌
x_l = self.ltx(x) # [B, HW, C']
# 将 x_l 还原回 2D 用于 GTX (此处为简化逻辑)
b, l, c = x_l.shape
h = int(l**0.5) # 假设输入是正方形
x_l_2d = x_l.transpose(1, 2).view(b, c, h, h)
# 提取全局令牌
x_g = self.gtx(x_l_2d) # [B, Global_Tokens, C']
# 交错合并 (Interleaved) 或 直接拼接 (Concat)
# 论文推荐 Interleaved 策略
return torch.cat([x_g, x_l], dim=1)
3. 实验表现
2D 任务:在 Endoscopy 数据集上,Dice 指数比 nnUNet 高出 26.5% 。
3D 任务:在 BraTS 2020 中达到 88.06% 的 Dice 分数,优于 SegMamba 等模型 。
计算效率:在提升性能的同时,维持了极低的 FLOPs。例如在 Cell 数据集任务中,FLOPs 仅为 51.7G 。
4. 总结
LoG-VMamba 的精髓在于它对“如何构建更具信息量的视觉令牌”的思考 。通过 LTX 锁定局部细节,GTX 注入全局视野,它让简单的单向扫描 Mamba 也能在复杂的医学图像任务中展现出超越 Transformer 的性能 。
项目完整代码开源地址:GitHub - Oulu-IMEDS/LOG-VMamba