一种利用特征交互与融合的有效 UNet 用于医学图像中的器官分割
作者
Xiaolin Goua,b,Chuanlin Liaoa,b,Jizhe Zhoub,Fengshuo Yec,Yi Lina,b*
a 合成视觉基础科学国家重点实验室,四川大学计算机学院,中国成都,610000
b 四川大学计算机学院,中国成都,610000
c 四川大学软件工程学院,中国成都,610000
*通讯作者:yilin@scu.edu.cn
文章信息
关键词: 通道空间交互、多级融合、医学图像分割、U 形模型
DOI: https://doi.org/10.1016/j.engappai.2026.113727
接收日期: 2024 年 9 月 29 日;修订日期: 2025 年 9 月 21 日;接受日期: 2026 年 1 月 2 日;在线发布日期: 2026 年 1 月 12 日
出版商: Elsevier Ltd.
摘要
如今,预训练编码器在医学图像分割中被广泛应用,因为其在提取丰富且泛化特征表示方面的强大能力。然而,现有的方法往往未能充分利用这些特征,从而限制了分割性能。本研究提出了一种新型 U 形模型(FIF-UNet),以解决上述问题,该模型包含三个即插即用模块。通道空间交互(CSI)模块通过建模编码器与解码器之间的跨阶段交互来提升跳跃连接特征的质量。解码器块中采用基于通道注意力的模块,将挤压-激励(SE)机制与卷积层集成,以强化关键特征表示并抑制无关特征。多级融合(MLF)模块设计用于聚合多尺度解码器特征,提升最终预测中的空间细节和一致性。在 Synapse 多器官分割数据集和自动化心脏诊断挑战(ACDC)数据集上的全面实验表明,所提模型优于现有的最先进方法,平均 Dice 分数分别为 86.05% 和 92.58%,分别提升了 1.15% 和 0.26%。此外,所提模型在准确性和计算复杂度之间实现了平衡,仅有 86.91 百万参数和 23.26 千兆浮点运算。
1. 引言
医学图像中的器官分割在医疗保健领域发挥着至关重要的作用,为诊断、治疗规划和临床决策提供基本的结构信息。器官的准确勾勒对于下游任务(如放射治疗规划、外科导航以及器官形态和功能的定量评估)至关重要。传统上,器官分割由专家临床医生手动完成,这耗时且易受人为错误和观察者间差异的影响。相比之下,自动器官分割方法可显著减少图像分析所需的时间和努力,从而提升临床效率。此外,通过最小化与人为相关的主观性,这些方法提供了更高的一致性、可重复性和准确性,这在高风险临床环境中尤为关键。
近年来,深度学习在各个领域取得了进步。卷积神经网络(CNN)能够实现图像的特征提取和表示,从而消除了手工特征的需求。在此背景下,基于 CNN 的自动分割工具通过神经架构从大量训练样本中学习图像特征,实现图像分割,并能以相当高的性能泛化到新任务(Azad et al., 2022a)。UNet(Ronneberger et al., 2015)由于其简单而有效的架构设计和高性能,成为医学图像分割中最受欢迎的框架,可应用于各种医学图像模态,包括 CT、MRI、X 射线、PET 等。UNet 通过带有跳跃连接的编码器-解码器架构实现。编码器通过多级特征提取和下采样操作逐步将图像转换为抽象表示。解码器基于抽象表示预测分割掩码,其中上采样操作用于恢复图像分辨率以生成像素级掩码(Purwono and Mangkunegara, 2023)。作为 UNet 的核心组件,跳跃连接将相邻编码器阶段和解码器阶段的特征结合,实现高效学习。
2. 相关工作
- CNN 模型: 在 2020 年 ViT 模型之前,基于 CNN 的 UNet 模型是医学图像分割领域的主导方法,通过卷积操作高效捕获局部特征。然而,原始 UNet 存在特征提取能力有限以及编码器与解码器之间语义差距的问题。为解决这些问题,UNet 的编码器或解码器模块被改进以增强特征学习。例如,在 DUNet(Jin et al., 2019)中,原始 UNet 的卷积层被可变形卷积层替换,以捕获复杂特征。Google-Net 的 inception 层(Punn and Agarwal, 2020)被应用于自动化选择深度网络中的层多样性。然而,上述改进主要基于局部卷积操作,仅具有弱的捕获全局上下文的能力。
- 视觉 Transformer 模型: Transformer 最初为自然语言处理提出,并在计算机视觉任务中开辟了新途径(Dosovitskiy et al., 2020)。Transformer 块允许输入序列中的每个元素通过自注意力机制关注所有其他元素,从而构建纯 Transformer 模型,以有效适应复杂图像场景和各种尺寸的对象,优于 CNN。例如,SwinUNet(Cao et al., 2022)使用具有移位窗口的分层 Swin Transformer 作为基本块,以学习全局和远距离语义交互。然而,与 CNN 相比,纯 Transformer 模型受限于局部特征的学习,这影响了详细特征的准确捕获,尤其是在精细的医学图像分割任务中。
- 混合 CNN-Transformer 模型: 混合 CNN-Transformer 模型利用 Transformer 在捕获长距离依赖和全局信息方面的优势,同时保留 CNN 在处理局部特征方面的效能。这种独特组合使混合模型在各种任务中实现前沿性能,尤其是在医学图像分割中。例如,在 TransUNet(Chen et al., 2021)中,CNN 用于提取局部特征,将输出投影到标记图像块,然后输入级联 Transformer 模块以学习全局特征。尽管结合 CNN 可以提升特征提取效率,但混合模型仍具有高计算复杂度,且正确整合 CNN 和 Transformer 的优势具有挑战性。
3. 方法
FIF-UNet 采用 U 形结构,具有对称的编码器-解码器模块。为确保完整性和可重复性,表 1 提供了详细的逐层配置。在编码器中,称为 MaxViT-S 的混合 CNN-Transformer 模型(Tu et al., 2022)作为骨干网络,在 ImageNet 数据集上使用图像分类任务预训练。相比全自注意力,MaxViT 基于块状局部和扩张全局注意力实现,仅具有线性复杂度(O(n),n 为输入图像的空间大小)。如图 2 所示,编码器网络包括 5 个阶段:一个茎阶段和四个级联 MaxViT 阶段。茎阶段中,两个卷积层具有 96 个通道和 3 的内核大小,第一 CNN 层的步幅设置为 2 以对输入图像分辨率下采样。MaxViT 的配置为 {2, 2, 5, 2} 个块,生成具有 {96, 192, 384, 768} 通道的特征图。
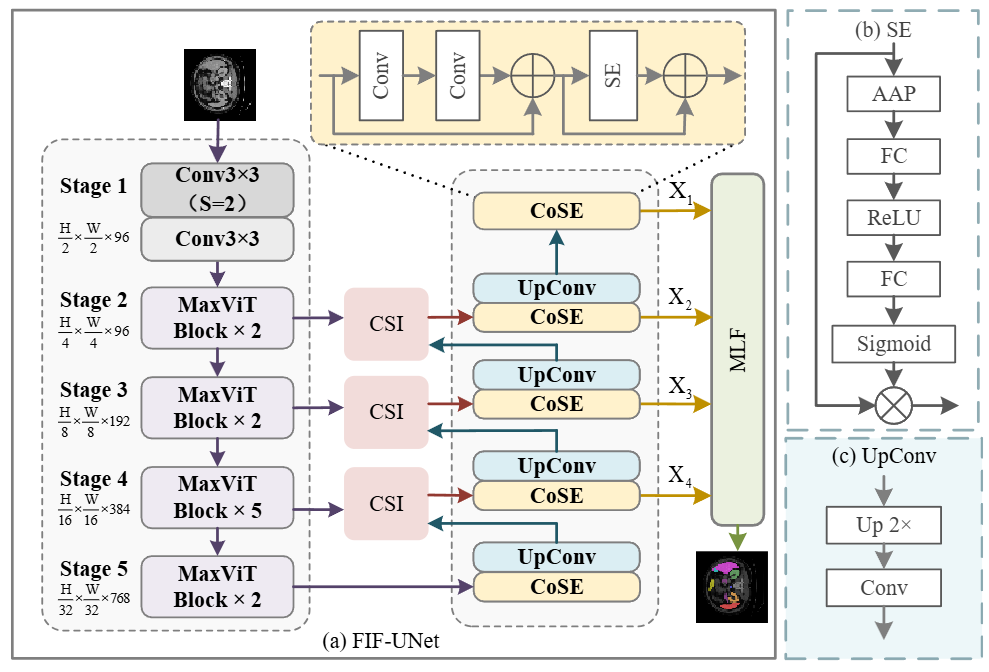
在跳跃连接中,CSI 模块通过设计的 CIU 和 SIU 动态重新校准特征图,以获得信息丰富的目标特征。在解码器网络中,每个解码器阶段基于 CoSE 模块和 UpConv 模块构建。CoSE 模块旨在通过将 SENet 机制集成到 CNN 中来增强关键特征的表示。UpConv 模块通过双线性插值上采样 CoSE 输出分辨率,随后使用卷积层精炼上采样特征图,如图 1(c) 所示。本工作创新性地提出 MLF 模块,以有效融合解码器阶段输出,通过整合类内和类间特征来增强分割细节,而不是仅基于最后一个解码器阶段预测分割任务。
-
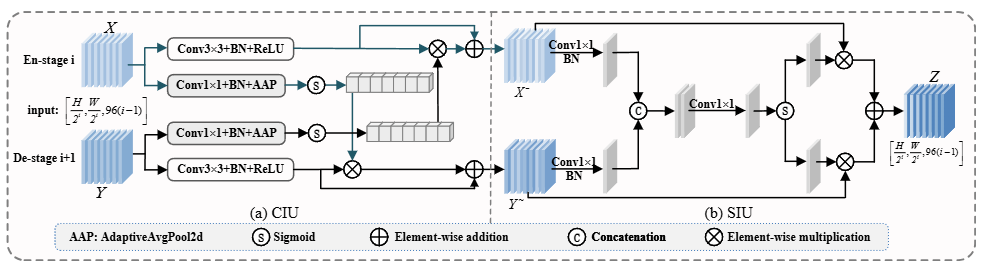
CSI 模块: CSI 模块由两个连续子单元组成:通道交互单元(CIU)和空间交互单元(SIU),如图 3 所示。CSI 应用于 UNet 架构的跳跃连接,输入为编码器阶段 i(i=2,3,4)和解码器阶段 i+1 的特征。该模块旨在通过学习自适应通道权重来在通道维度对齐编码器和解码器特征,并捕获特征之间的空间相关性,以提升跳跃连接特征的语义质量。
-
CoSE 模块: 在原始 UNet 中,解码器阶段仅由两组(CNN、BN 和 ReLU)组成。为区分复杂背景中的关键特征,将通道注意力 SENet(Hu et al., 2018)集成到解码器阶段中。CoSE 模块由卷积块和 SENet 构建,并在卷积块和 SENet 前分别添加残差连接,以确保稳定训练和有效特征传播。
-
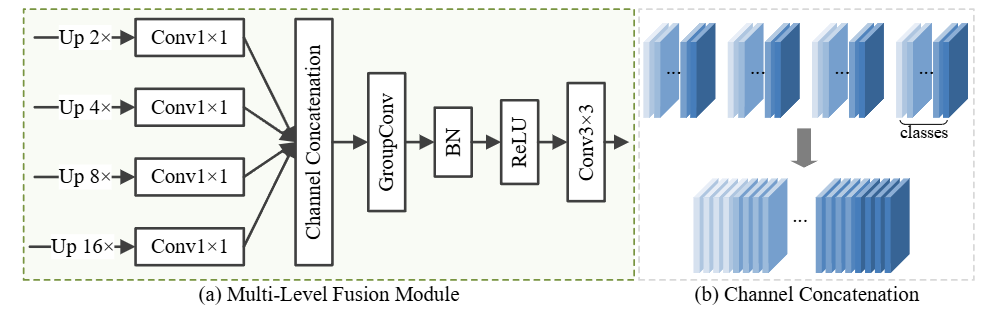
MLF 模块: MLF 模块(如图 4 所示)显式融合不同解码器阶段的多尺度特征。通过可学习融合操作实现更丰富的跨尺度特征交互,以保留空间细节。解码器阶段 1–4 的输出特征图被上采样 2、4、8 和 16 倍,并通过逐点卷积映射到任务相关的类数。随后,进行通道串联以组合每个类的特征,最后使用两步卷积块(组卷积和标准卷积)整合类内和类间特征以生成分割掩码。
损失函数基于加权 Dice 损失和交叉熵(CE)损失,并引入多阶段特征混合损失聚合(MUTATION)方法(Rahman and Marculescu, 2024)以增强模型收敛。
4. 实验与结果
-
数据集: Synapse(30 个腹部 CT 扫描,8 个器官;18/12 训练/测试拆分)和 ACDC(100 个 MRI 扫描,3 个心脏结构;70/10/20 训练/验证/测试拆分)。
-
实现: 输入大小 256×256;AdamW 优化器;400 个 epoch;批量大小 16;使用 Dice 和 HD95 指标评估。
-
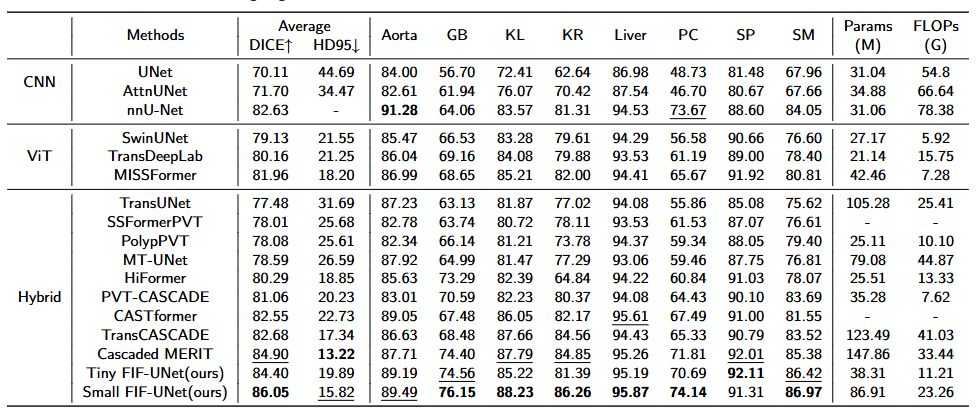
Synapse 定量结果: 小型 FIF-UNet 实现平均 Dice 86.05%(vs. Cascaded MERIT 的 84.90%)和 HD95 15.82,在小器官如胆囊(+1.75%)和胰腺(+2.33%)上获得提升。微型变体平衡效率(38.31M 参数,11.21 GFLOPs)。
-
ACDC 定量结果: 平均 Dice 92.58%(vs. Parallel MERIT 的 92.32%),具有统计显著性(p=0.033)并降低复杂度。
-
消融研究: 每个模块贡献约 0.9–1.5% Dice 提升;完整集成在 Synapse 上 +1.48%,在 ACDC 上 +0.64%。Dice+CE 损失优于备选方案。
-
跳跃增强比较: CSI 优于 AG、FFM、GAB、SCCSA(+0.48–1.99% Dice)。
-
泛化: 模块将原始 UNet 提升高达 3.92% Dice。
-
定性结果: 可视化显示相比 SwinUNet 和 MERIT,具有优越的边界勾勒和减少误分类。
-
失败案例: 挑战包括边界模糊和类不平衡;建议不确定性建模和高级增强。
5. 结论
FIF-UNet 通过优化特征交互与融合,提升了医学图像分割的前沿准确性,同时保持高效计算。未来增强可整合不确定性估计,以解决剩余的边界和不平衡问题。